如果要說哪家公司是目前全球最炙手可熱的公司,相信很多人第一時間的答案一定是老黃的英偉達。
在前不久公布的2023年度財報當中,英偉達營收達到了609.22億美元,淨利潤297.6億美元,同比分別增長126%和581%。
橫向比較一下,英特爾2023年營收542億美元,淨利潤16.89億美元,同比分別下降14%和78.9%,AMD營收226.8億美元,淨利潤8.54億美元,同比分別下降3.9%和35.3%,英偉達在同類型公司中可謂鶴立雞群。
因為AI革命的發生,英偉達的晶片在過去一年一直處於供不應求的狀態,以至於它的毛利率達到了恐怖的72.7%,超過了茅台。
那麼作為一家高科技企業,英偉達接下來是會擠牙膏收割毛利,還是進一步創新推高AI算力呢?就在今天早上的GTC2024上,黃仁勛給了我們答案。
想要快,就要大!想要晶片速度更快,該怎麼辦?
那就造的大一些!這是黃仁勛今早在GTC2024上給出的答案。
這個大晶片,是目前英偉達,或者說這個地球上最快的AI計算晶片,它就是全新一代的BlackWell GPU晶片。

GTC2024

左側為BlackWell,右側為Hopper
與上一代的Hopper相比,新一代的晶片在面積上的確大出了不少。老黃解釋道,這是因為一塊完整的BlackWell晶片,其實是由兩塊同架構的小晶片構成。

兩塊小晶片合成一個完整的BlackWell
因為製程從之前的台積電4N工藝升級到了現在的4NP工藝,所以即使單個小晶片的電晶體也比之前提升了200億個,當兩個小晶片合在一起後,一塊完整的BlackWell晶片的電晶體數量達到了驚人的2080億!要知道,上一代的Hopper規格只是800億。

完整的BlackWell擁有2080億個電晶體
在顯存方面,新晶片依然採用了HBM3E規格的顯存,但是容量從141GB提升到了現在192GB,頻寬從4.8TB/S提升到了8TB/S。
除了電晶體帶來的計算能力提升,在架構上,英偉達對於FP4這個精度的計算也做了一些優化,在這個精度上,計算能力相比上代提升了5倍,其它的精度上,BlackWell的提升大約在2.5倍左右。這就像給一台發動機在增大的排量的同時,還給內部進行了一些優化,雙管齊下,跑的更快了。

FP4精度不高,但響應快,因此一般都用在大模型的推理當中,優化過後,使用新晶片進行推理的速度提升了30倍。
也就是說,如果把目前的ChatGPT中的GPU都換成BlackWell,那麼我們得到回答的速度將會有著至少十幾倍的提升。拋開專門的FP4優化,在正常的大模型訓練下,採用新晶片的GB200計算卡,要比老款H100快上2.5倍到4倍。
演講中,老黃並沒有提到配備一個GPU晶片的B200或者B100,只拿出了配備了2塊GPU+1塊CPU的GB200。其中的CPU依然是上一代ARM架構的Grace,只是GPU有了升級。

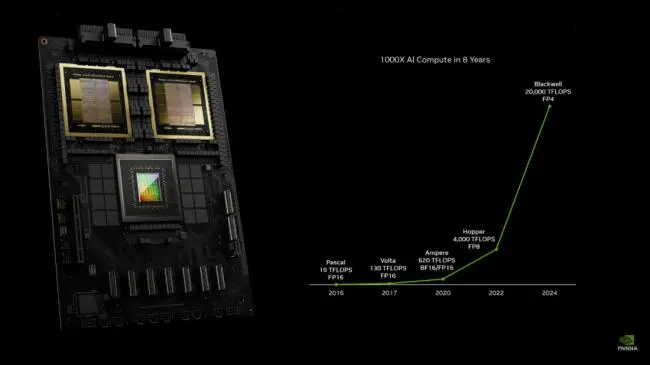
在展示BlackWell的後半段,老黃還回顧了從2016年開始,英偉達顯卡在計算速度上的提升,雖然精度略有不同,但可以看出,這幾年老黃在計算卡上確實沒有擠牙膏,每次算力的提升都是實打實的。
超級計算機的新骨骼
除了晶片更強外,老黃在晶片互聯之間也有大幅更新。
比如組成BlackWell的兩個小晶片,它們之間的互聯速度就達到了10TB/S,按照老黃的說法,這個速度已經可以滿足晶片緩存(Cache)的要求,可以完全把它看作一個單獨的大晶片。
英偉達引以為傲的NVlink,也算是這次最佳配角,全新的NVLink交換機頻寬提升到了7.2TB/S。NVLink交換機的存在,就像人體的骨骼和血管一樣,它的存在,把各個GPU計算節點連接在一起,讓它們更好的發揮,協同。

這次NVLink的提升,72個的GPU可以連接在一起,組成一個DXG超級計算機,並且可以讓整個計算機被看做一個超級大的GPU來用。
為了達到72個GPU之間的高速互聯,DXG內部總共使用了3.2公里長的光纖線纜。

這樣一台DXG伺服器在訓練AI時候的算力達到了恐怖的720 PFLOPs,6年前老黃親手把DXG初代機交給馬斯克和OpenAI的時候,那台機器的算力只有0.17 PFLOPs,6年時間,DXG伺服器的算力提升了3600倍!

在介紹GPU的最後,老黃用大家熟悉的GPT做了一個非常量化的比較,他說目前的OpenAI最先進的模型的參數是1.8萬億個。
在使用A100 GPU訓練的時候,需要25000個,耗費時間3-6個月,到上一代H100,數量降低到8000塊,時間壓縮到90天,需要消耗1500萬度電,如果用最新的BlackWell GPU,訓練時間沒變,依然是90天,但是GPU的數量將縮減至1/4,電量只需要400萬度。
老黃依然沒有忘記元宇宙
2個小時的演講中,前一個小時圍繞著硬體,後一個小時則是軟體的「推廣」。
NIM是英偉達新推出的一種大模型部署「傻瓜化服務」,只要你的顯卡支持CUDA,那麼就可以非常簡單的利用NIM來部署和微調出屬於自己業務的大模型。
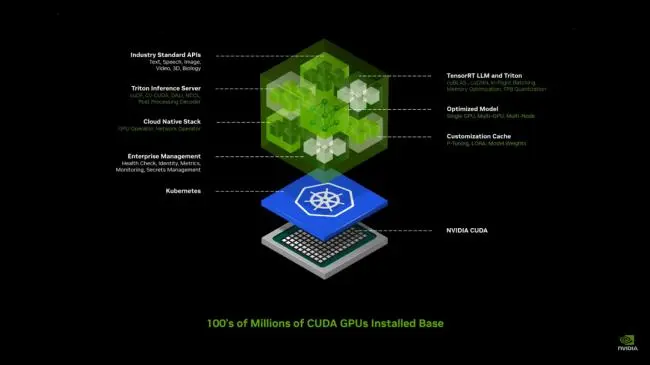
剩下的時間,老黃都在介紹它的「元宇宙」——Omniverse。只不過和以前單純的把所有的東西都數位化不同,Omniverse現在更多的扮演了AI和現實世界中的中間層。
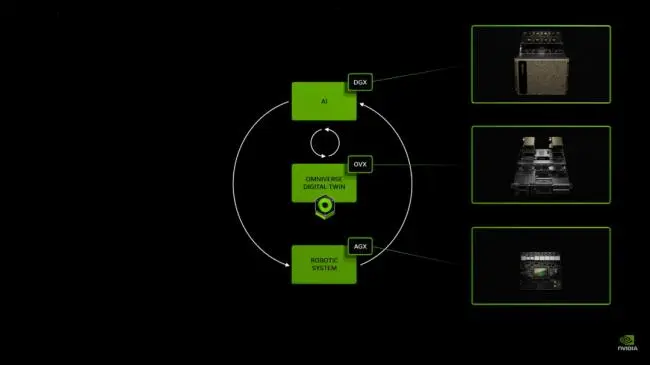
AI雖然能做到很多事情,但無法直接感覺現實世界,它只能通過各種資料來學習,從來沒有實際上手過,就像經驗值為0的小菜鳥。如果想讓AI做到完美的控制機器,就要儘可能的讓AI去現實世界中練習。
但現實練習的成本太高了,比如讓AI管理一個倉庫,總不能讓工人,貨物和機器人一起作AI的「陪練」。這個時候Omniverse就派上用場了,它對於現實物理的完美模擬,可以讓AI在虛擬工廠中進行訓練。
在老黃的例子中,Omniverse通過數字孿生把自動化工廠和工廠中搬運機器人聯繫起來。在工廠中,有一堆貨物從貨架上掉下來。
視頻中AI會根據工廠中工人的位置,貨物掉落的位置,為搬運機器人指出一條既不干擾工人工作,也不會被貨物絆倒的路線。有過這樣的經驗,AI在現實中碰到同樣的情況就可以妥善處理了。

在訓練之後,人類還可以直接和AI對話,讓它重現剛才發生的情況以及它的對策。
除了工業,老黃還啟動了Gr00t計劃,同上面一樣,這也是一個AI,Omniverse,現實的三層結構。只不過這次它應用在機器人身上。
機器人通過AI,人類遠程示教來進行學習,然後在Omniverse這個「虛擬鍛鍊場」進行各種鍛鍊,最終達到在現實中完成任務的目的。

演講的最後,老黃還請出了一排機器人和兩個裝有英偉達Jetson處理器的小機器人,雖然和小機器人的溝通演示有些失敗,但是對於一些像跟隨,停止等基本指令,小機器人還是執行到位了。

人類已經處在AI發展的快車道上
簡單總結下老黃的這次演講,有兩大重點。
第一,當然是AI算力的進一步提升,基於你的不同應用場景,新一代的英偉達晶片將帶來2.5倍到30倍不等的算力提升。
這意味著我們將看到更強大的模型,以及更快的模型響應速度,具備實用性的視頻圖文語音多模態模型也將成為可能。這一塊是英偉達市值翻倍的動力,也是接下來很長一段時間的中心所在。
第二,在大模型的應用場景上,老黃的目標,是從現在的白領服務業領域,向數字孿生,向工業,向機器人的方向擴展。
2024年我們將看到AI更多的出現在現實世界,特別是人型機器人的時代可能很快就會到來。
這確實是個讓人害怕又興奮的大時代。




















{kind=link}