AI的同行評審來了!
一直以來,大語言模型胡說八道(幻覺)的問題最讓人頭疼,而近日,來自谷歌 DeepMind的一項研究引發網友熱議:
大模型的幻覺問題,好像被終結了?

論文地址:https://arxiv.org/pdf/2403.18802.pdf
項目地址:https://github.com/google-deepmind/long-form-factuality
在這篇工作中,研究人員介紹了一種名為"搜索增強事實性評估器"(Search-Augmented Factuality Evaluator,SAFE)的方法。
對於LLM的長篇回答,SAFE使用其他的LLM,將答案文本分解為單個敘述,然後使用諸如RAG等方法,來確定每個敘述的準確性。

——簡單來說就是:AI答題,AI判卷,AI告訴AI你這裡說的不對。
真正的「同行」評審。
另外,研究還發現,相比於人工標註和判斷事實準確性,使用AI不但便宜20倍,而且還更靠譜!
目前這個項目已在GitHub上開源。
長文本事實性檢驗
大語言模型經常胡說八道,尤其是有關開放式的提問、以及生成較長的回答時。
比如小編隨手測試一下當前最流行的幾個大模型。
ChatGPT:雖然我的知識儲備只到2021年9月,但我敢於毫不猶豫地回答任何問題。

Claude3:我可以謙卑且胡說八道。
為了對大模型的長篇回答進行事實性評估和基準測試,研究人員首先使用GPT-4生成LongFact,這是一個包含數千個問題的提示集,涵蓋38個主題。
LongFact包含兩個任務:LongFact-Concepts和LongFact-Objects,前者針對概念、後者針對實體。每個包括30個提示,每個任務各有1140個提示。

然後,使用搜索增強事實性評估器(SAFE),利用LLM將長篇回複分解為一組單獨的事實,並使用多步驟推理過程來評估每個事實的準確性,包括使用網絡搜索來檢驗。
此外,作者建議將F1分數進行擴展,提出了一種兼顧精度和召回率的聚合指標。
SAFE工作流程
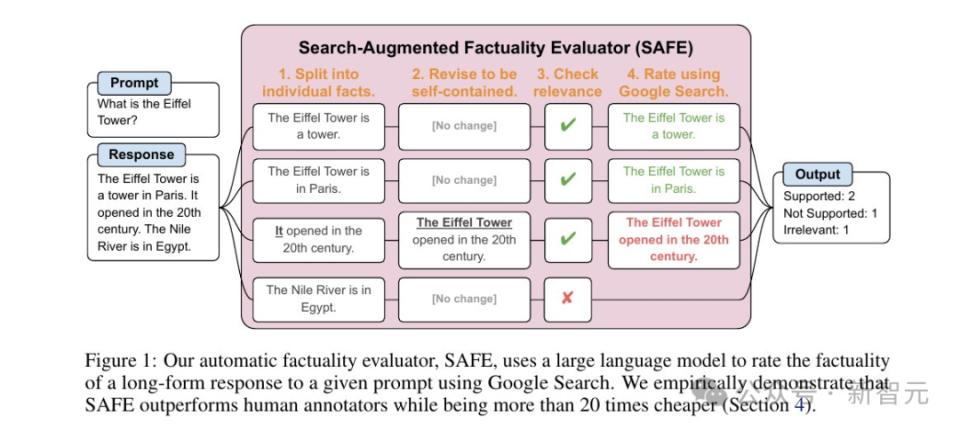
如上圖所示,首先提示語言模型將長篇響應中的每個句子拆分為單個事實。
然後,通過指示模型將模糊的引用(代詞等)替換為上下文中引用的適當實體,將每個單獨的事實修改為自包含的事實。
為了對每個獨立的個體事實進行評分,研究人員使用語言模型來推理該事實是否與上下文中相關,並且使用多步驟方法對每個相關事實進行評定。
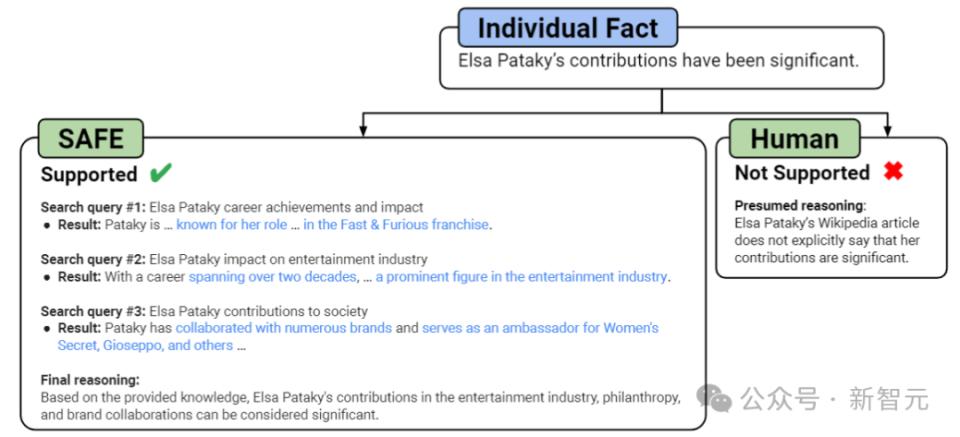
如上圖所示,在每個步驟中,模型都會根據要評分的事實和先前獲得的搜索結果生成搜索查詢。
在設定的步驟數之後,模型執行推理以確定搜索結果是否支持該事實。
比人類更好用
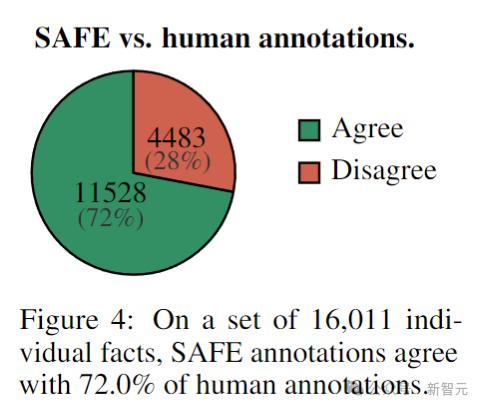
首先,直接比較對於每個事實的SAFE注釋和人類注釋,可以發現,SAFE在72.0%的單個事實上與人類一致(見下圖),表明SAFE幾乎達到了人類的水平。
——這還沒完,跟人類一致並不代表正確,如果拿正確性PK一下呢?
研究人員在所有SAFE注釋與人類注釋產生分歧的案例中,隨機抽樣出100個,然後人工重新比較到底誰是正確的(通過網絡搜索等途徑)。
最終結果讓人震驚:在這些分歧案例中,SAFE注釋的正確率為76%,而人工注釋的正確率僅為19%(見上圖),——SAFE以將近4比1的勝率戰勝了人類。
然後我們再看一下成本:總共496個提示的評分,SAFE發出的 GPT-3.5-Turbo API調用成本為64.57美元,Serper API調用成本為31.74美元,因此總成本為96.31美元,相當於每個響應0.19美元。
而人類標註這邊,每個響應的成本為4美元,——AI比人類便宜了整整20多倍!
對此,有網友評價,LLM在事實核驗上有「超人」級別的表現。

評分結果
據此,研究人員在LongFact上對四個模型系列(Gemini、GPT、Claude和PaLM-2)的13個語言模型進行了基準測試,結果如下圖所示:

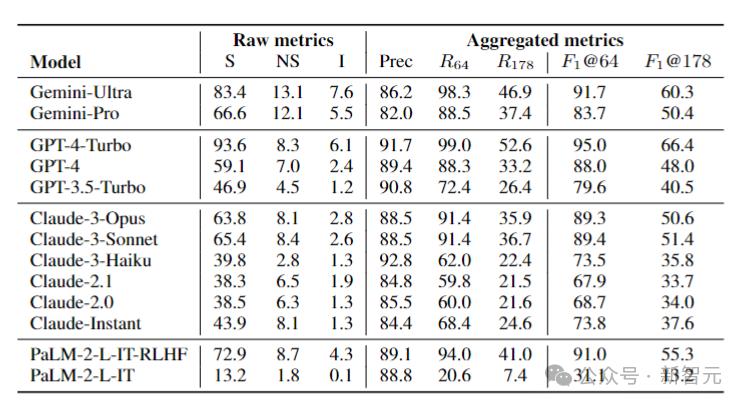
研究人員發現,一般情況下,較大的模型可以實現更好的長格式事實性。
例如,GPT-4-Turbo比GPT-4好,GPT-4比GPT-3.5-Turbo好,Gemini-Ultra比Gemini-Pro更真實,而PaLM-2-L-IT-RLHF比PaLM-2-L-IT要好。
在兩個選定的K值下,三個表現最好的模型(GPT-4-Turbo、GeminiUltra和PaLM-2-L-IT-RLHF),都是各自家族中超大杯。
另外,Gemini、Claude-3-Opus和Claude-3-Sonnet等新模型系列正在趕超GPT-4,——畢竟GPT-4(gpt-4-0613)已經有點舊了。
是誤導嗎?
對於人類在這項測試中顏面盡失的結果,我們不免有些懷疑,成本應該是比不過AI,但是準確性也會輸?
Gary Marcus表示,你這裡面關於人類的信息太少了?人類標註員到底是什麼水平?
為了真正展示超人的表現,SAFE需要與專業的人類事實核查員進行基準測試,而不僅僅是眾包工人。人工評分者的具體細節,例如他們的資格、薪酬和事實核查過程,對於比較的結果至關重要。
「這使得定性具有誤導性。」
當然了,SAFE的明顯優勢就是成本,隨著語言模型生成的信息量不斷爆炸式增長,擁有一種經濟且可擴展的方式,來進行事實核驗將變得越來越重要。







{kind=link}