沒想到,在ChatGPT爆火後的一年裡,竟然出現了一個隱藏「Boss」——
量子位獲悉,百度、360等網際網路大廠均已開始基於昇騰部署AI模型;而知乎、新浪、美圖這樣全速推進AI業務的公司,背後同樣出現了華為雲昇騰AI雲服務的身影。
明面上,大模型帶動了N卡炙手可熱;但另一面,國產算力提供者中的頭部企業華為也浮出水面。
有意思的是,上述提到的玩家,目前展現的共性也非常明顯:無一例外都是有場景的網際網路玩家。
簡單解釋,就是這些公司在大模型變革之前,基本都在各自的行業中有穩定的業務生態,也有核心的商用場景。
毫無疑問,他們需要更快更高效讓大模型引擎轉動,可以更快產生最直接的價值,雲算力是最合適的選擇。
國內算力市場,悄然生變
解題就得從大背景展開,國內算力市場的供給和需求,正在產生方向性變化。
首先是資源的供給,也就是提供算力的市場,出現了變化。
從去年開始,國內市場就出現了「N卡難求」的情況。為此英偉達輪番推出特供版GPU,在算力和功率上一再縮水,但還是受到限制。最近才有風聲的HGX H20和兩款新的GPU,也被曝可能推遲到明年2月或3月才能發布。
一系列算力供給縮水動作,使得國內市場上已有的英偉達系列顯卡進一步稀缺,算力一個月內漲價50%甚至100%已是常態。
據《經濟參考報》介紹,由於算力資源持續緊張,國內算力服務公司如匯納科技,已經在11月中旬擬將所受託營運的內嵌英偉達A100的高性能算力伺服器算力服務收費同步上調100%。
與此同時,國內網際網路廠商因大模型急速增長的算力需求,又加劇了這種緊張的局面。
先是國內大模型數量激增,10月份統計數據顯示,國內已發布了238個大模型。
每一個大模型背後都意味著海量算力的投入,綜述《A Survey of Large Language Models》顯示,650億參數大模型LLaMA,在2048塊80G A100上訓練了21天;而700億大模型LLaMA2,同樣用了2000塊80G A100訓練。
然而,AI算力需求還會持續上漲。
據OpenAI測算,自2012年以來,人工智慧模型訓練算力需求每3~4個月就翻一番,每年訓練AI模型所需算力增長幅度高達10倍。
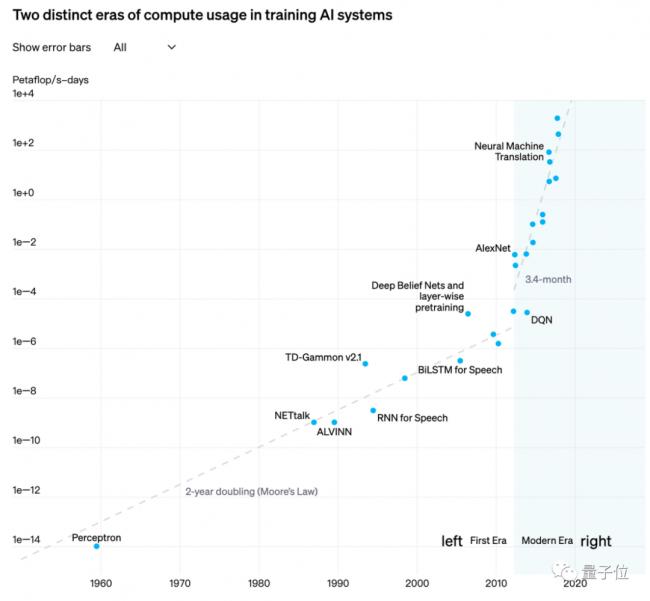
△
圖源OpenAI
顯然,隨著AI成為全球產業的增速引擎,算力作為背後的驅動力自然關注不小,甚至出現了「誰能爭搶到算力,誰就更有先發權」這樣的說法。
一方面,如果算力跟不上,無法搭上AI這班快車,直接面臨的結果就是在競爭中落於下風,甚至可能被行業拋棄。
360公司創始人周鴻禕曾經談到,公司如果沒有搭上ChatGPT這班車,很有可能會被淘汰。
與之相反,如果及時跟進潮流,公司就能憑藉已有場景,快速在行業競爭中獲得優勢。像是一度裁員12%的美版頭條BuzzFeed,在宣布和OpenAI合作使用ChatGPT幫助創作內容後,股價一度暴漲119%。
另一方面,算力的充足與否,又直接決定了擁有AI技術和產品的公司,能否提供長期穩定的服務,從而在這場競爭中擁有先發權。
即使是在這場潮流中占據主導話語權的OpenAI,也面臨算力緊張而無法滿足用戶需求、被迫將用戶「拱手相讓」的問題。
例如前不久,ChatGPT出現了幾次流量過大、伺服器承載不下導致應用響應崩潰的情況,導致國外用戶爭相湧向谷歌Bard和Anthropic的Claude2;付費訂閱產品GPT-4,同樣因為伺服器流量爆炸而出現「暫停訂閱」的情況。
但當下算力受限的情況,導致傳統網際網路企業要想快速跟上AI大模型相關的業務,無法再單單依靠「買卡」這一條路。
畢竟光是等待算力龍頭如英偉達發卡的時間,很可能就已經錯過了這一波風口。
相比之下,有場景的網際網路玩家,一旦有合適的算力,就能更快接入AI大模型相關的業務,從而在這場競爭中獲得先發話語權。
在這樣的需求下,像華為雲這樣的國產算力玩家,再度成為國內網際網路廠商們關注的對象。
作為有算力、能提供雲服務、最早適應大模型打法的雲廠商之一,華為雲究竟為何能在一眾算力供給者中脫穎而出,為有場景的玩家們所看好?
為什麼是華為雲?
在行業調研中,行業玩家們對大模型時代的雲服務,有4大普遍性訴求:
算力可持續
高效長穩
簡單易用
開放兼容
而之所以選擇華為雲,從其「對症下藥」的技術細節就能管窺一二。
其架構由下至上,包括AI算力、異構計算架構、AI框架、AI平台、大模型、工具鏈幾個層級,由此構成一個算力充沛、高效穩定、低門檻廣生態的雲底座。

1、算力可持續
可持續的算力能從最根本上緩解行業玩家們的算力焦慮,同時也是大模型快速煉成、應用落地的基本保障。
在這方面,華為雲打造了貴安、烏蘭察布、蕪湖3大AI雲算力中心,提供3大主節點及30+分節點,支持AI算力即開即用。
昇騰AI集群也在今年全面升級,集群擴展至16000卡,成為業界首個萬卡集群。它可支持萬億參數大模型分布式訓練。
此外在保障算力資源合理分配方面,華為雲支持資源彈性伸縮,可根據業務需求實際情況,自動增加或縮減伺服器實例或頻寬資源,可在保障業務能力的同時節約成本。

2、穩定高效
先來看穩定性。
由於大模型訓練過程比傳統分布式訓練更複雜,導致訓練所需計算集群規模空前增加、涉及器件數量往往在百萬/千萬級別。如果單器件發生故障,就可能導致集群訓練中斷,且故障原因定位定界複雜。
這就使得當前大模型訓練更容易出現故障,訓練時間被拉長。
以Meta的OPT-17B訓練為例,理論上在1000個80G A100上訓練3000億個單詞,需要33天。實際訓練卻使用了90天,期間出現了112次故障。其中主要問題是硬體故障,導致手動重啟35次,自動重啟約70次。
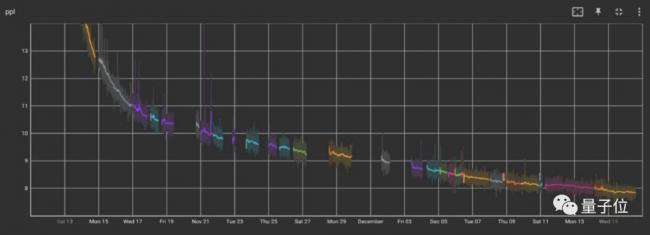
△OPT-175B意外中斷情況
在這方面,華為雲昇騰AI雲服務支持裸金屬集群進行大模型訓練,無虛擬化損失,並行訓練效率提升100%。從處理器、算子、框架、平台全鏈路垂直協同優化,主力場景性能是業界平台的1.5倍以上。
以盤古大模型(2000億參數)在2048卡上的訓練為例,實現了30天訓練不中斷,長穩率達到90%,斷點恢復時長控制在10分鐘以內。
此外華為雲還實現了千卡預訓練故障自動診斷恢復,增強智能運維工具能力,實現分鐘級信息獲取、2小時定界、24小時提供解決方案。

華為常務董事、華為雲CEO張平安
再來看高效性,這是場景玩家們的迫切需求。
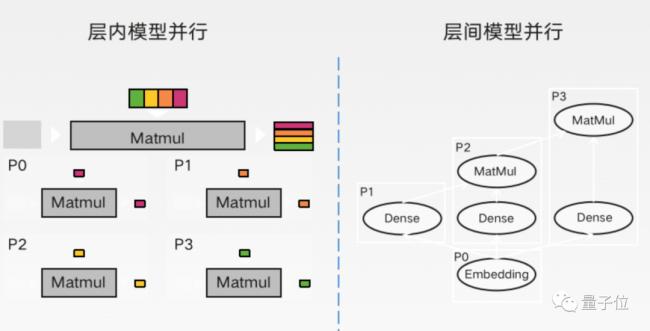
但是千億參數大模型在訓練中需要大量的梯度、參數等進行同步,集群很難實現線性加速比。即,增加了一倍的計算集群規模,但是計算量無法同比增加。比如:
1024卡集群:計算和通訊比例為7:3
2048卡集群:計算和通訊比例為4:6
華為雲昇騰AI雲服務通過模型+集群的混合併行策略,讓模型切分更加平衡,從而實現集群接近線性加速比。
1024卡集群:計算和通訊比例為85:15
2048卡集群:計算和通訊比例為80:20
4096卡集群:計算和通訊比例為70:30
以及在訓練成本方面,華為雲昇騰AI雲服務使用CAME優化器,相較於業內常用方案可節約50%記憶體用量。
要知道,大模型的海量參數會導致訓練時記憶體消耗空前增加,進一步導致訓練成本升高。CAME優化器專為大模型訓練而來,獲得了2023年ACL傑出論文獎。
3、簡單易用降低開發門檻
如今ChatGPT引爆的大模型趨勢已經全面鋪開,來自千行百業的玩家們都迫切想要快速將大模型接入自己的業務中。
但是大模型開發又是一個複雜的系統工程,從頭開始自己摸索會影響落地速度。
所以雲服務廠家們紛紛推出了簡單易用的開發工具。比如華為雲提供了全鏈路工具鏈,雲化免配置、開箱即用,可實現5倍速開發大模型。
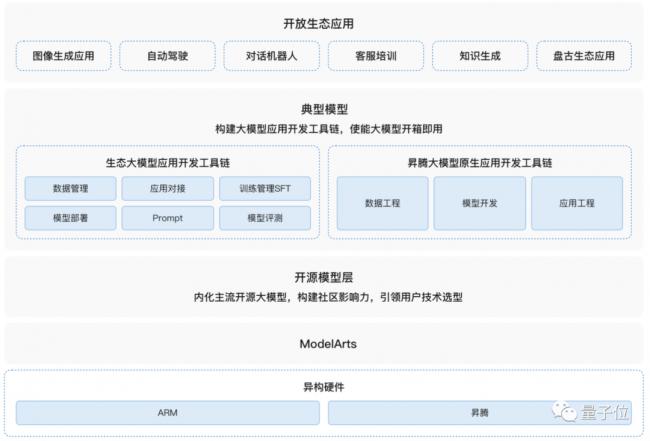
它包括大模型開發工具套件,可自動化、半自動化數據工程,效率提升3倍,5分鐘快速構建應用開發。
調試調優部分包含1400+算子沉澱,30+可視化調優部署工具;提供豐富的API能力,可調用盤古大模型100+能力集。
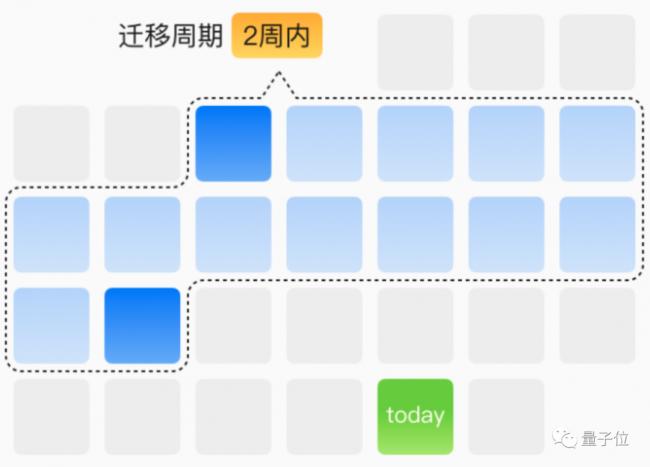
還能將典型模型遷移效率提升到2周內搞定,實現主流場景自主遷移。
4、構建開放兼容生態
最後,並非所有場景玩家都需要從頭構建大模型。選擇在已有基礎大模型上進行微調或者直接使用,是更加降本增效的方案。
那麼對於開發者、行業玩家而言,有更多選擇就很重要了。
基於這一點業內需求,華為雲上線了百模千態社區,企業和開發者能直接使用業界主流的開源大模型,如Llama、GLM等。同時聚合數據集、模型、實踐等10萬+AI資產。
為了滿足開發者的不同偏好,昇騰AI雲服務已兼容TensorFlow、PyTorch、RAY、Caffe等AI框架。
進入昇騰AI雲服務百模千態專區,僅需3步即可開發自己的大模型。
基於如上雲服務能力,華為雲已經給業內諸多玩家提供了大模型使能服務。
比如美圖僅用30天就將70個模型遷移到了昇騰,同時華為雲和美圖團隊一起進行了30多個算子的優化以及流程的並行加速,AI性能較原有方案提升了30%。
崑崙萬維和華為雲簽署戰略合作,雙方將在華為雲昇騰算力領域展開全面深入合作,致力於打造企業專屬模型,支持企業級AI應用,持續賦能千行萬業應用創新與場景落地。

華為雲CTO張宇昕
在當前算力稀缺、資源不足的情況下,這些場景玩家選擇與華為雲這樣的雲廠商聯手,來快速增強自身「AI硬實力」。
而這種大背景之下,也涌動著當前的產業趨勢:
技術創新的曲線開始趨於平緩,商業創新的曲線開始發力。
其中,增速最快的,自然是有場景、有業務的玩家。
場景玩家如何把握AI落地機遇
ChatGPT發布一年以來,AIGC已行至下半場。
上半場,國內外掀起一股基礎大模型技術爭鋒浪潮,「百模大戰」態勢之下,湧現出一批AI初創公司。
這些公司或掌握底層AI架構基礎、或有搭建上層AI工具的經驗,依靠技術發布了不少有創意且吸睛的產品,融資更是拿到手軟。
然而,隨著相關技術逐漸從開疆拓域走向穩定成熟,AIGC產業也出現了新的變化。

下半場,AI技術公司開始追求產業落地,不少初創公司更是在尋求擴大生態圈的方式。
相比之下,有場景的網際網路公司,通過觀察AIGC技術優勢,依託生態優勢、加上算力基礎,就能快速擴大影響力,進而在公司中取得話語權。
在這種情況下,技術和場景玩家的身位也在悄然發生變化——
技術玩家,需要「拿錘找釘」,面臨進一步擴張技術生態和產品場景的難題。
雖說這些玩家已經具備了成熟的基礎大模型或工具鏈技術,但技術仍舊需要找到場景,才能進一步穩定出圈。
相比之下,場景玩家成為了「拿釘找錘」的一方。
依託已有場景需求和穩定用戶生態,這些玩家只需將AIGC技術融入業務,就能進一步實現降本增效。
然而,即便是AIGC技術趨於成熟的當下,想要快速跟進也並非易事,除了底層的算力搭建以外,大模型所需的訓練和加速等技術也並非就能「一蹴而就」。
在這樣的下半場態勢中,像華為雲這樣底層算力、AI相關技術和平台、生態三者齊備的國內雲廠商,在場景玩家的發展中進一步起到了催化劑的作用。
底層算力上,華為雲依託自研的昇騰處理器打造的超大規模AI集群,已經由4000卡升級到16000卡集群,能支持萬億級模型訓練,不僅速度更快,訓練周期也更穩定;
AI相關技術和平台上,除了AI算力之外,華為雲還為開發者提供了完善的工具和資源,解決了AI大模型部署從訓練、加速到不同框架適配這些難題,進而基於已有的研發經驗,給廠商提供營運所需的技術服務;
AI生態上,華為雲已經與150多傢伙伴、200多家客戶,共同構築了20多個行業大模型以及400多個AI應用場景,加速行業智能化升級。
所以,在當前國際大環境下,有場景的玩家,只需要藉助像華為雲這樣的雲廠商提供的技術服務,就能快速將下半場大模型機遇變成紅利,而華為雲也能給國內的網際網路企業提供更多選擇。
現有的趨勢,也能說明這一點。
美圖首個懂美學的AI視覺大模型發布當天,股價單日上漲21.28%,隨後更是受到國內圖像編輯工具行業的廣泛關注;
拓維信息發布的交通CV大模型,如今已在高速公路稽核等行業場景得到應用,這1年一來股價上漲了129.44%……

顯然,這些玩家基於自身已有的業務,再依託雲廠商提供的大模型和算力,就能快速將場景勢能發揮到最大優勢。
但無論選擇什麼類型的雲廠商、做出怎樣的判斷,國內網際網路企業都依舊需要回到當前的大環境下,結合客觀形勢做出判斷。
在國外算力購買愈發困難的當下,面臨新一輪AI競爭趨勢,如何讓算力像水電一樣即取即用,是所有國內企業都應當要思考的問題。
事實上,如今中國的算力水平實際上已經位居世界第二,占全球市場比重達25%,從2017年到2022年的複合增長率達到48.8%。
當更多的企業願意投資算力、交易算力,就能推動算力產業進一步降本增效,加快算力向現實生產力轉化。



















{kind=link}