如何更順滑的添加水印?谷歌的這項新技術,讓文本簡直就像貼在地面上,哪怕是在沙塵橫飛的場景里。

方法也很簡單。
只需輸入一段視頻,和指定對象的粗略蒙版。
那這個對象的所有相關場景元素,都能解鎖!
不管是任意對象和主體,不論怎麼移動,所有元素都能摳出來。
這就是谷歌最新的視頻分層技術——omnimatte,入選 CVPR2021 Oral。
目前這項技術已開源。

如何實現
計算機視覺在分割圖像或視頻中的對象方面越來越有效,然而與對象相關的場景效果。
比如陰影、反射、產生的煙霧等場景效果常常被忽略。
而識別這些場景效果,對提高 AI的視覺理解很重要,那谷歌這項新技術又是如何實現的呢?
簡單來說,用分層神經網絡渲染方法自監督訓練 CNN,來將主體與背景圖像分割開來。
由於 CNN的特有結構,會有傾向性地學習圖像效果之間的相關性,且相關性卻強,CNN越容易學習。
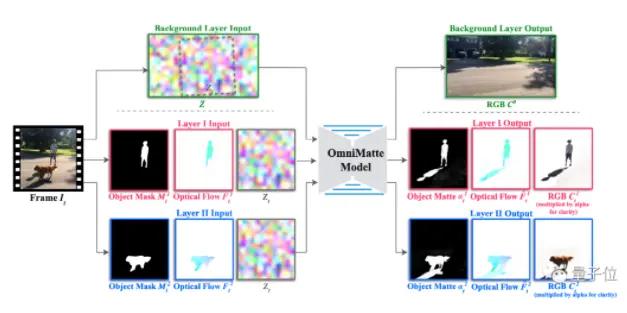
輸入一段有移動物體的視頻,以及一個或者多個標記主體的粗略分割蒙版。
首先,使用現成的分割網絡比如 Mask RCNN,來講這些主體分成多個遮罩層和背景噪音圖層,並按照某種規則進行排序。
比如,在一個騎手、一輛自行車以及幾個路人的場景中,就會把騎手和自行車歸入一個層,把人群歸入第二層。
omnimatte模型是一個二維 UNet,逐幀處理視頻。每一幀都用現成的技術來計算物體掩碼,來標記運動中的主體,並尋找和關聯蒙版中未捕捉到的效果,比如陰影、反射或者煙霧,重建輸入幀。
為了保證其他靜止的背景元素不被捕獲,研究人員引入了稀疏損失。
此外,還計算了視頻中每一幀和連續幀之間的密集光流場,為網絡提供與該層對象相關的流信息。
最終生成 Alpha圖像(不透明度圖)和 RGBA彩色圖像,尤其 RGBA圖像,簡直可以說是視頻/圖像剪輯法寶!

目前這一技術已經開源,配置環境如下:
Linux
Python3.6+
英偉達 GPU+ CUDA CuDNN
有什麼用途
技術效果如此,那有什麼樣的用途呢?
首先就可以複製或者刪除圖像。

還有順滑地切換背景。



















{kind=link}