隨著感染者越來越多,這一輪疫情的「進度」、我們何時能恢復正常生活正被廣泛討論。
其中,「大數據」尤為公眾所關心。
12月15日前後,一組預測各城市首輪感染高峰期的截圖,在朋友圈和微信群中廣泛流傳。
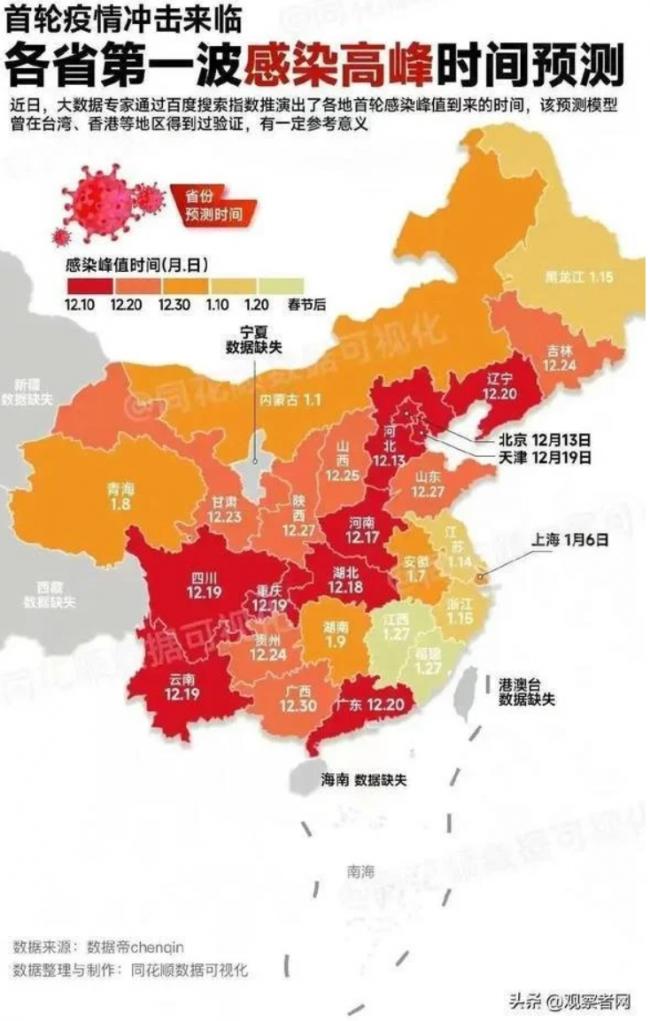
圖中,給出了全國各省區主要城市的疫情進度和最終高峰的預測時間表,且這個數據在不斷更新。
以石家莊、北京、鄭州3城為例,最早的版本是,截至12月10日,第一波群體感染達峰石家莊已經完成了77%,北京是29%,鄭州11%。
12月12日,在製作者開發的小程序上,數據更新為:石家莊完成84%,北京是38%,鄭州是15%。
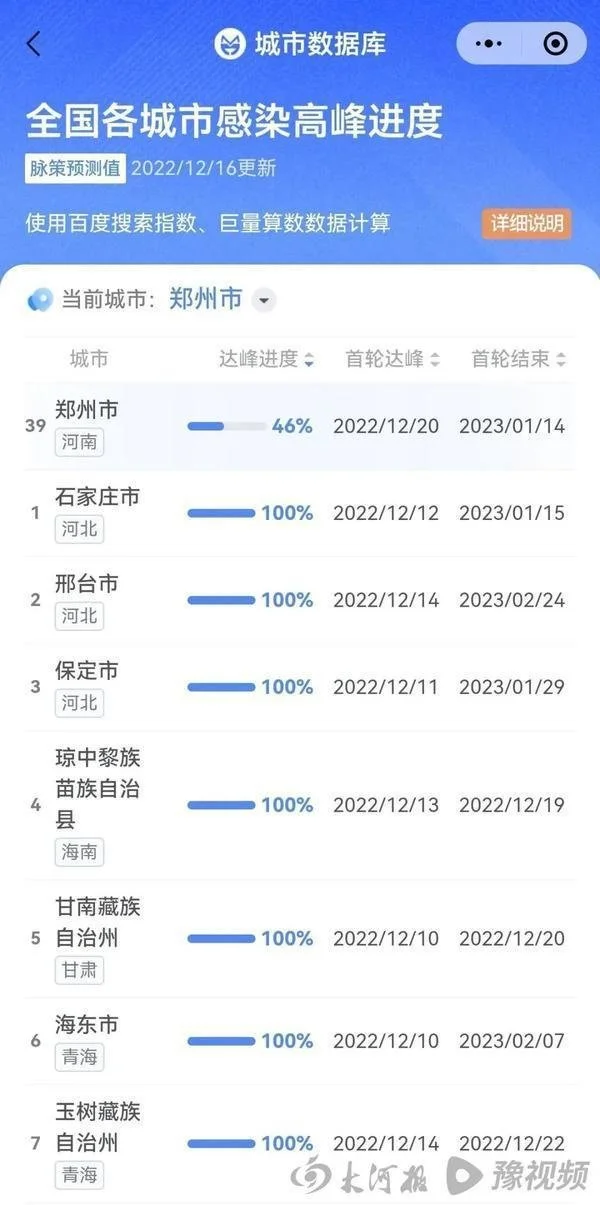
最新版本停在了12月16日,石家莊已完成100%,北京87%,鄭州46%。
而此時,三個城市的累計感染人數占總人口比值分別為49%,35%,19%。
這組數據的原作者,是知乎大V@chenqin,「數據帝」、「2021新知答主」是他的標籤。
據其預測,截至12月16日,石家莊、保定、邢台等多地「達峰進度」均已達到100%。
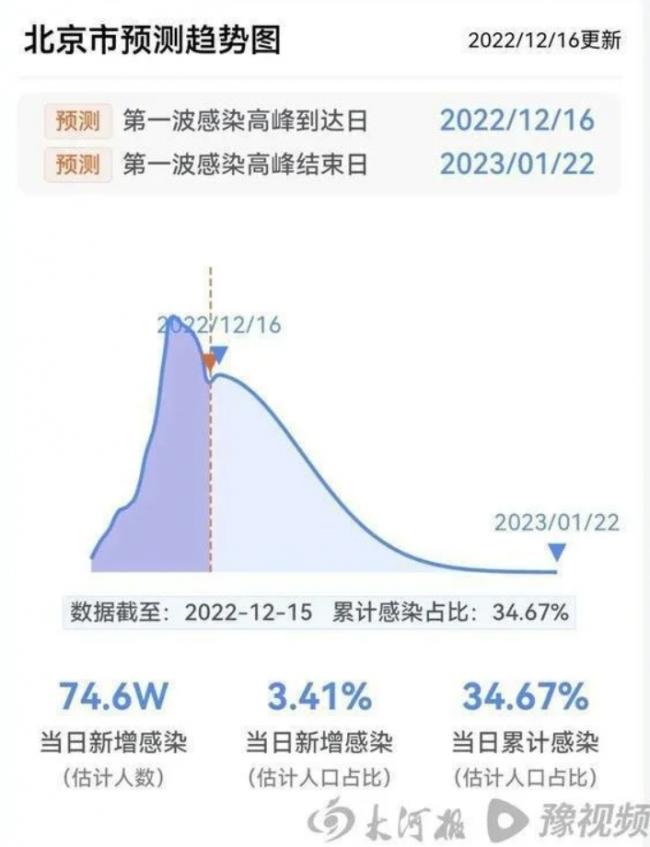
北京市將於2023年1月22日結束首輪感染高峰,上海市將於2023年1月18日結束首輪感染高峰,鄭州市將於2023年1月14日結束首輪感染高峰。
那麼,這個預測時間表的依據是什麼,又是否靠譜?
12月15日以來,針對算法和數據等疑問,記者多次聯繫@chenqin本人,但未獲得回應。
不過,@chenqin在自己發布的文章中對自己的初衷和方法,有過介紹。
「我又對台灣地區、香港特別行政區和日本的感染情況與『發燒』搜索指數進行了分析,發現一個可能可以幫助預測感染高峰期的方法。」

他的方法是,根據百度搜索的數據,分地區統計關鍵詞「發燒」的搜索數據,減去非疫情時期的常量,最終根據港台、國外等多個地區的樣本擬合出來的走勢,對比推算出了各地區疫情的進度。
簡言之,當某一城市有人在百度上搜索「發燒」,就為其判斷這座城市的疫情情況提供了參考數據。
而談及這麼做的初衷,@chenqin說,疫情達峰時間的推算,原本只是搜索指數的一次嘗試,初衷是覺得有趣,但無心插柳,竟然能幫助許多人緩解焦慮,「我還是會希望繼續更新下去,讓這份粗糙的數據陪伴大家渡過第一次衝擊」。
截至12月17日,@chenqin發布的《各城市首輪感染高峰期預測》,包含各城市感染峰值日期、進度、第一波疫情結束時間、累計感染占比等,已經在知乎上獲得了1.1萬贊同,其數據被自媒體廣泛引用,並曾登上熱搜。
有網友給答主點讚,稱這個方法雖然「簡單粗暴」,但邏輯是對的,通過搜尋引擎數據預測流感流行趨勢是有不少論文發表的。
也有網友稱,數據跟自己所在城市的感受並不一致,「保守了」。
更多網友則寧可信其真,跟帖話題轉向與數據「嚴重程度」相當的疫情見聞。
專家:有一定參考價值
但有優化空間
通過搜尋引擎數據建立模型預測疫情走勢,該預測數據的參考價值有多大?
「僅通過搜索數據建立起來的預測模型,準確度通常並不高。」天使投資人、資深人工智慧專家郭濤告訴記者。
郭濤說,疫情傳播速度受到感染人群的數量及活動軌跡、人口流動信息、居民生活方式、交通條件、醫療條件和天氣條件等綜合因素影響,如果想要實現預測,就需要搞清楚影響疫情傳播的因素到底有多少,它們之間又是如何相互影響的,僅通過搜索數據是不夠的。
「美國早年曾用搜索數量進行過相關的預測,在一定程度上它是可以反映疫情整體的傳播速度和爆發量的。」北京社科院研究員、大數據業務分析師王鵬教授接受記者採訪時則表示,依據搜索大數據來預測新冠疫情感染高峰,實際上在國外也早有相關的應用。
針對不同城市,預測感染何時達到頂峰、退卻、第一波進度等,在一定程度上,無論是對公共政策的制定者、政府、還是公眾來說,都有一定參考價值,有助於大家了解疫情的走勢。
但是從現實角度出發,目前運用搜尋引擎,尤其是僅依託於百度的數據,王鵬覺得可能有所失真。
移動網際網路時代和PC端時代有差異,首先現在很多人不一定都在手機端搜索,即使手機端的搜尋引擎也有很多源,不一定都用百度,國產的其他搜尋引擎也很多。另外,很多人可能不在搜尋引擎上進行搜索,也可能在社交平台或短視頻平台搜索,所以說相關的搜索數量,數據本身是存在一些問題的。
第二,在這個自媒體時代,大家搜索一個關鍵詞,不一定自身有症狀,可能是家人或朋友有症狀。而且在一定程度上,我們陷入了信息繭房,換句話說,我們在網際網路搜尋引擎上搜索最多的人群,可能是特定的人群,他們的收入水平、年齡、對網際網路的熟悉程度相當。剩下絕大多數人群,對網際網路運用得少,或者壓根不上網,是「沉默的大多數」,所以完全依託於搜索的數據來推測疫情,肯定不是特別精準的。
王鵬也建議,PC端和移動端數據都需考慮到,數據來源也不應該僅是搜尋引擎,應該把社交媒體、短視頻平台數據都納入。同時,算法不應該太簡單,還應該進行多元的優化重組,進一步訓練,才能得出更為精準的結論。



















{kind=link}