
在過去的一年裡,中國政府一直在進行一些最新的實驗,以建立管控人工智慧 (AI) 的監管工具。
在此過程中,中國正試圖解決世界各國政府即將面臨的一個問題:監管機構能否深入了解算法的運作,並確保它們在可接受的範圍內運行?
一個特別的工具值得關注,既因為它在中國的影響,也因為其他國家的技術專家和政策制定者可以從中吸取經驗:中國網際網路監管機構為算法推薦服務而創建的強制註冊機制。
儘管這種註冊的全部細節並未公開,但通過深入研究其在線說明手冊,我們可以對中國新興的算法監管架構,有新的洞察。
註冊系統的建立
這個算法註冊系統,是根據中國 2022 年的《網際網路信息服務算法推薦管理規定》(英譯:China’s 2022 regulation on recommendation algorithms)而創建的,該規定於今年3月生效,由「國家網際網路信息辦公室」(Cyberspace Administration of China,CAC) 牽頭。中國的算法監管,主要集中在算法推薦服務在信息傳播中的作用,要求服務提供者確保其不「危害國家安全或社會公共利益」,並在損害用戶合法利益時「作出解釋」。其他條款試圖解決平台的壟斷行為和社會熱點問題,例如在給中國送貨司機製造危險的勞動狀況方面,調度算法所起的作用。
該《規定》還要求,具有「輿論屬性」(public opinion characteristics)和「社會動員能力」(social mobilization capabilities)的算法推薦服務,必須向名稱神秘的「網際網路信息服務算法備案系統」(Internet Information Service Algorithm Filing System),完成備案。但這些規定沒有詳細說明具體內容,而備案要求在當時基本沒有引起注意。
2022年8月,「國家網際網路信息辦公室」(CAC)發布了第一批30個算法的註冊文件,分析人員才第一次看到了這些文件。通過註冊網頁可訪問的這些文件,有中國最大的一些網際網路平台公司的算法,包括騰訊、阿里巴巴和字節跳動。這些公開可訪問的文件,通常是單一的頁面,其中有6個不同的簡短回復類別,包括「算法基礎」和「算法運行機制」。
但這些備案文件中的實際描述過於籠統,幾乎完全缺乏有意義的細節。例如,微博「熱搜」功能的備案文件,將算法描述為「搜索熱度、討論熱度和傳播熱度」相加,乘以「互動率係數」(interaction rate coefficient)。這可能是一個準確的描述,但它的標準也很高,以至於不了解該特定算法的觀察者基本上可以猜到它。如果這是提供給中國監管機構的全部信息,那麼關於算法、算法如何訓練或算法如何執行,它將不會給監管者提供任何有意義的認知。
來自用戶手冊的啟示
但是,仔細查看算法註冊的登陸頁面,其中包含一個可下載的用戶手冊,供註冊其算法的實體使用,從中可以更廣泛地了解「網信辦」實際在收集什麼信息。仔細閱讀該手冊並檢查其中的截圖,就會發現,提交註冊備案的信息中只有部分被披露。
手冊中最詳細的披露要求,來自於一張截圖,該截圖顯示了披露「詳細的算法屬性信息」的頁面。在這裡,它要求算法提供者列出用於訓練模型的每個開源和自建數據集的名稱,以及該數據的具體來源。此外,它要求提供者說明,算法輸入是否涉及生物特徵識別(biometric)或其他個人信息。
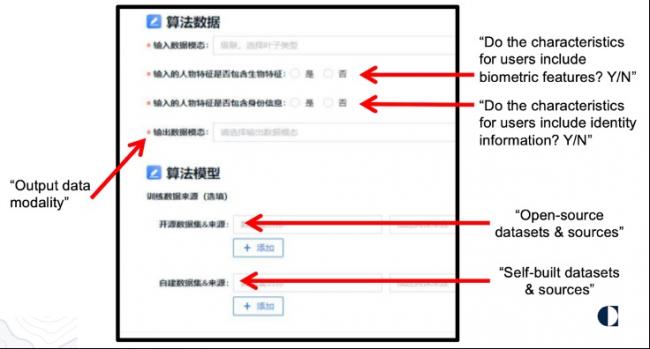
圖1. 算法註冊用戶手冊的注釋截圖
在一個標題為「算法基本屬性信息」頁面的單獨截圖中,公司被要求上傳「算法安全性自我評估」的PDF文件。由於這些上傳文件不對公眾開放,我們無法確切知道其中需要哪些信息,也不知道安全性是如何定義的。鑑於該規定強調控制信息的傳播,安全性自我評估可能涉及對公共言論的控制,將匹配已註冊的算法類型,包括「處理非法信息和內容」的「安全風險識別」算法。但它也可能包括其他問題,如濫用「生成式人工智慧模型」(generative AI models)和「對抗性攻擊」(adversarial attacks)。

圖2:算法註冊用戶手冊的注釋截圖
其他截圖概述了可能需要更多信息的其他部分的標題——「算法策略」、「算法風險和預防機制」——但用戶手冊沒有提供這些頁面的截圖,因此所需披露的信息仍然是個謎。
通過查閱用戶手冊,我們發現,註冊機構對中國公司的要求,比我們之前所了解的,既有更多的一面,也有更少的一面。更多的一面,是因為該手冊揭示了重要的新的披露要求,而這些要求並未出現在文件的公開版本中。列舉數據集的要求是不言自明的,而算法安全性的自我評估,既可以粗略,也可以全面。關於要求更少的一面,是因為有些人曾經認為,註冊備案的要求,意味著中國政府現在可以直接獲取算法或底層代碼。但情況似乎並非如此,進一步的報告支持這一結論。
中國以外的比較
最直接相似的監管,存在於歐盟的《數位服務法案》(Digital Services Act,DSA)中,這是一項全新的法律,對推薦算法的透明度和審查,提出了更大的要求——儘管我們還沒有看到算法透明度在該法中採取什麼形式。當這些被公開時,它們將構成另一個值得關注的算法透明度實驗。
另一個可能與中國這項實驗類似的,是在人工智慧倫理社區中推廣「模型卡」(model cards)的運動。「模型卡」最初由谷歌和多倫多大學的研究人員在一篇論文中提出,被定位為「朝著機器學習的負責任的民主化邁出的一步」。大多數「模型卡」提供了一個模型的理想輸入形式的簡單概述,可視化了一些潛在的限制,並提出了基本的性能指標以反映現實世界的影響。就像中國註冊機構的備案一樣,許多「模型卡」提供了關於架構、應用場景、訓練數據和敏感數據使用的信息。
但是,模型卡傾向於強調性能評估,而中國的算法註冊則強調安全評估。在某些情況下,重點可能會重疊;模型卡可能有安全組件,一些提交的備案側重於減輕對邊緣化群體的負面影響,例如從事食品配送工作的移民。但一般來說,模型卡通過比較一個模型在不同人口群體中使用時的表現,來解決對算法偏見的擔憂。模型卡既面向專家,也面向非專家的受眾。相比之下,中國的算法註冊,面向的是政府和提出各種備案的機構,而中國公民並沒有被邀請去評估偏見。相反,這仍然是政府的職權範圍,政府可以定義什麼是安全和風險。目前的註冊體制反映並強化了中國共產黨作為這些問題的最終仲裁者的角色。
隱藏在所有這些實驗背後的,是一個更深的問題:對複雜算法如何運作,在技術上是否有可能獲得有意義的透明度?深度學習經常被描述為一種「黑盒子」(black box)技術,因為它所做的預測、決定和建議不容易解釋,即使對它的開發者也是如此。算法的可解釋性,是機器學習研究的一個活躍領域,但主要問題仍然是何時——如果有這個時間的話——它將達到在監管背景下有用的水平。
「網信辦」可能還缺乏體制內的專業技能,無法理解公司提交給算法註冊的信息。一份報告描述了「字節跳動」的代表和「網信辦」之間的會議,在會議中,字節跳動的員工「不得不依靠比喻和簡化語言的組合 「,來與官員溝通。
中國的下一步行動
對於這樣一個雄心勃勃的項目,這聽起來可能不是一個有利的開始。但在建立新的監管架構時,你必須從某個地方開始。在算法註冊之前,中國官員不知道什麼是他們不知道的。通過提供對中國有影響力的算法的大概了解,註冊系統可以提醒「網信辦」在哪些方面可能缺乏有用的信息,並為其提供依據,以進一步要求公司披露信息。
在這個意義上,目前構建工具來監管算法的努力,與中國早期試圖控制網際網路訪問和自由的社交媒體平台的做法,正相呼應。在這兩種情況下,中國政府的努力都顯得笨拙,而且經常被描述為徒勞無功。但是,通過慢慢形成對技術和行業的了解,中國政府能夠加強控制,直到達到一個符合其目的平衡點。現在,我們將看看它是否能在算法方面玩出同樣的把戲。















{kind=link}