生成式AI的這股浪潮翻湧到現在,已經一年多了。
如果要論在這股浪潮中,哪一類模型是AI領域「王冠上的寶石」,那一定是文生視頻模型莫屬。
從技術層面來說,Sora、Vidu這列視頻大模型,最核心的價值,在於它們實現了跨媒介的信息合成與創造,從而形成了文本、圖像、與視頻等不同模態的「大一統」。
而這樣的「大一統」,或許正是人類通向AGI的關鍵。
在這個「大一統」的框架下,數據不再被單一模態所限,而是作為多維度信息的綜合體被理解和運用。
正如圖靈獎得主,AI三巨頭之一的Yann LeCun所提出的「世界模型」理論所述,現如今的 LLM(大模型)都只是在文本上訓練的,因此只能非常粗淺地理解世界。
即使 LLM憑藉大量參數和海量訓練數據,能展現出過人的文本理解能力,但它們本質上捕獲的依然只是文本的統計規律,並不真正理解文本在現實世界中所代表的含義。
而如果模型能使用更多感官信號(比如視覺)學習世界的運作模式,那麼就能更加深刻地理解現實。從而感知
那些無法僅憑文字傳達的規律、現象。

AI三巨頭之一 Yann LeCun
從這個角度來說,誰能率先通過多模態的世界模型,讓AI掌握現實物理的規律,誰或許就能率先突破文本和語義的限制,在通往AGI的路上先登上一個大台階。
這也是為什麼,OpenAI當前如此傾注於Sora的原因。
雖然前段時間,Vidu的出現給國產視頻技術長臉了,在Sora這樣的行業霸主面前挺直了腰板,但大傢伙兒在歡欣鼓舞的同時,細心一看Vidu的演示視頻,發現個挺有意思的事兒:
裡面老外的臉蛋特別多。

這一下子,可讓大傢伙兒琢磨開了,感覺像是無意中扯出了咱們在收集視頻資料這塊兒的一個小辮子——高質量數據不足。
數據之困
如果說,現階段真有制約視頻生成模型發展的硬門檻,那麼這樣的門檻,無非就是算力、算法與數據。
而其中的前兩者,實際上只要有錢,有人才,實際上都能搞得定,唯獨數據,一旦落下了,後面想追平,可就得費老大勁兒了。就像身高一樣,拉開了就很難追趕。
講真,雖然從絕對總量來看,中文網際網路上視頻內容也不少了,但其中真正可用於AI訓練的高質量數據,卻並不如外網豐富。

例如,在視頻目標檢測方面,YouTube視頻數據集VIS包含2,904個視頻序列,共超過25萬個標註目標實例。國內視頻目標檢測數據集,如華為的OTB-88,僅包含88個視頻序列。
而在行為識別數據集方面,由國際上同樣知名的HACS數據集,包含了140萬個視頻片段,涵蓋200個人類日常行為類別。相較之下,國內阿里雲的天池行為識別數據集,雖然也是涵蓋200個行為類別,但僅僅包含了20萬個視頻片段。
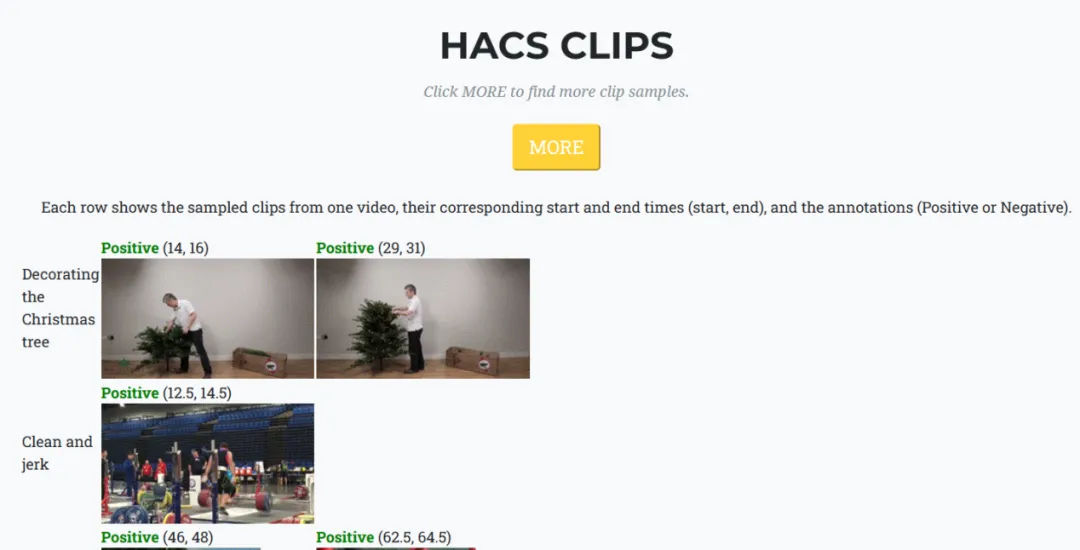
造成這一差距的原因,從視頻生態上來說,主要是因為國內的很多主流視頻網站,例如愛優騰,發布的大都是一些影視劇、綜藝、娛樂等內容。
而流量最大的抖音、快手這些短視頻平台,也都是滿屏的搞笑段子、生活小竅門,本來時長就很短了,其中還不乏很多剪輯、搬運、抄襲的作品。
這麼一來,AI想找點「正經飯」吃,還真不容易。
對於視頻AI訓練來說,這樣的視頻,要麼過於集中於特定類型,缺乏日常生活等多樣化的場景,要麼時長太短,缺乏深度和連貫的敘事,這不利於AI學習到長序列的連貫性、故事邏輯和因果關係。
與之相比,專業團隊製作的電影、紀錄片等內容,往往才是視頻AI所需的高質量數據。
因為這些題材不僅種類豐富,時長夠長,並且十分重細節呈現,更有利於AI模型捕捉到光線變化、物體材質方面的區別,從而提升其生成的精準度。
視頻數據這塊兒地兒,咱們不光是缺高質量的內容,還有個頭疼的事兒——數據標註,這可是塊難啃的骨頭。就算視頻拍得質量再高,但你直接甩給AI,它也不能分清其中的物品。
所以收集好視頻數據後,得有人耐著性子,一幀一幀地告訴AI:「瞧見沒,這條線動的是車流,那個兩腳走路的是行人。」

要搞定數據標註這個既費勁又海量的活兒,沒點厲害的傢伙事兒可不成。例如,為提升標註效率,國外就湧現出了一批互動式視頻標註工具,如CVAT, iMerit等。這些工具集成了自動跟蹤、插值等算法,能夠大幅減少人工標註的工作量。
反觀咱們國內,由於自動化標註工具不那麼普及,多半還是靠人海戰術,大批的標註小分隊加班加點地手動肝。
這麼幹吧,雖說標註的量上去了,可問題也跟著來了——這批臨時拉起來的大軍,沒個統一的、客觀的標準,培訓啥的也不到位,全憑個人感覺在那兒判斷對錯好壞,這樣一來,數據質量參差不齊就成了常態,有的地方標得好一些,有的地方可能就馬馬虎虎。

更讓人頭大的是,這種活兒,不僅枯燥乏味,累死累活,還掙不了幾個錢,你說誰樂意干長久?
根據多家視頻數據標註公司的反饋,大多數標註員的月薪在3000-5000元之間,國內視頻標註行業的
年流失率普遍在30%-50%之間,個別公司甚至高達80%。
這行當人員流動跟走馬燈似的,公司得不停地招新人、培訓新人,剛教會一批,轉頭又走了一波。這直接把數據標註的質量穩定性給攪和了。
講真,在數據總量、多樣性、標註環節均不如外網的情況下,國內的視頻AI要想崛起,該怎麼跨過數據這道難關呢?
合成數據
如果高質量數據實在難找,那走合成數據這條路,用人工素材來「投餵」AI,是否可行呢?講真,在Sora問世前,就已經有人這麼做了,例如英偉達在2021年發布的Omniverse Replicator就是這樣一個例子。

說白了,Omniverse Replicator就是個合成數據的平台,專攻那種超逼真的3D場景。這玩意兒牛就牛在,它造出來的視頻數據啊,每個細節都嚴絲合縫地遵循物理定律,就像是從真實世界裡直接摘出來的一樣。
這玩意兒對誰最管用?哦,那可多了去了,自動駕駛,機器人訓練什麼的,或者任何想要AI準確理解物理動態的項目。
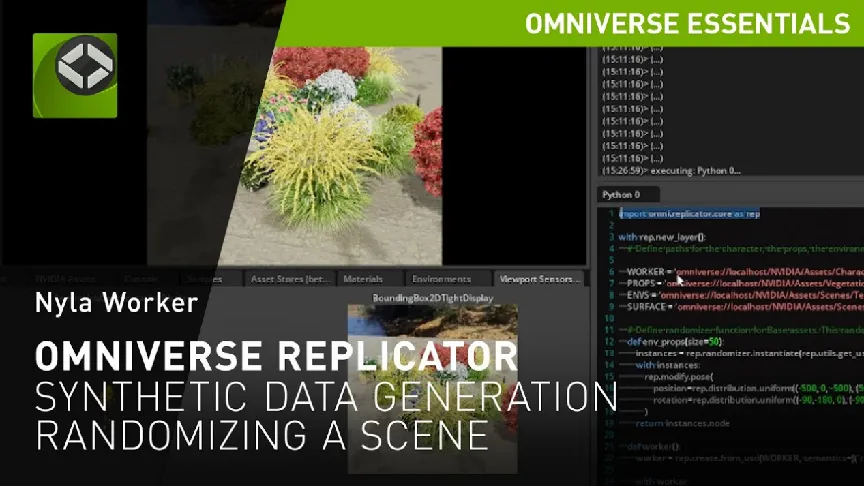
在進行數據合成時,Omniverse Replicator首先會將各種3D模型、貼圖和真實的材質拖進自己的平台中,之後就像搭積木那樣,用這些素材構建出各種場景,例如城市街道,工作中的車間,或者是繁忙的馬路等等。
接下來,為了讓製造出來的數據不那麼「死板」、「單調」,Replicator有個厲害的功能,就是能讓人設定很多變化的因素。比如物體放哪兒、朝哪邊、長啥樣、顏色咋變、表面摸起來啥感覺,甚至是燈光怎麼打,都能讓它自己隨機變來變去。
這樣做有個大好處,就是能讓最後得到的數據五花八門,能讓AI見識各種情況。
這對AI數據合成來說,是至關重要的一步。

再之後,為了精確模擬現實中的物理交互,Omniverse Replicator中的NVIDIA PhysX等物理引擎,會根據牛頓力學等物理法則,在物體發生碰撞或接觸的時候啊,計算它們的運動狀態改變,比如速度、加速度、旋轉和摩擦力等。
同時添加重力、彈性、摩擦力、流體阻力等約束條件,從而讓模擬更接近現實。

雖然Omniverse Replicator可以生成高質量的視覺和動態3D場景,但它最擅長的是處理那些遵循物理定律的東西,比如怎麼讓虛擬的球按正確的方式彈跳。而對於那些抽象的,具有連貫邏輯和敘事性的內容,就超出了它的能力範疇了。
比如,如果人們想在視頻里展現一個人開心的樣子,就得讓AI先學會「笑」這個表情,這可不是物理模擬能搞定的東西……
再比如,人們喝完水後,如果杯子不是一次性的,人們往往就會將水杯放回原位,而不是隨手丟掉,這樣的行為,其實更多地遵循的是人類常識,而不是純粹的物理規律。
在理論上,Omniverse Replicator無法單獨生成訓練Sora這類視頻模型所需的所有數據,特別是那些涉及高級語義理解、連貫敘事和高度抽象概念,以及複雜的人類情感和社會互動的實例,這些都是Omniverse Replicator目前的設計和功能範圍之外的。
另闢蹊徑
實際上,除了Omniverse Replicator這種路子外,使用虛幻5引擎生成相關數據,也是一種備選策略。
在之前Sora放出的視頻中,人們就已經發現,某些視頻片段的效果,跟此前寫實、逼真的畫風有點不一樣,看上去更像是某種「3D風格」,例如下面的這個大眼睛、長睫毛、口噴冷氣的小白龍。

雖然OpenAI官方並未承認,但眼尖的網友一看就感覺到了,這玩意兒有虛幻5的影子!
但即使這種猜測是真的,虛幻5能提供的,大概率也只是對光線、場景、3D信息和物理交互的模擬數據,本質上和Omniverse Replicator一樣,只能提供一些很「硬」的物質層面的模擬。
要真想搗鼓出一個啥都有的世界級視頻大雜燴數據集,就得想想新招。
一個挺極端的法子就是讓AI自產自銷,自己造視頻來訓練自己。但這裡頭有個坑,要是這些AI親手做的視頻在訓練材料里占太多了,就會出現「模型自噬」的風險。
換句話說,就是生成的東西越來越差。
在極端情況下,持續使用自我生成的數據,可能會導致模型性能急劇下降,甚至模型完全失效,因為AI可能會將前代模型的缺陷一代代放大。
去年,萊斯大學和斯坦福團隊發現,將AI生成的內容餵給模型,只會導致性能下降。
研究人員對此給出一種解釋,叫做「模型自噬障礙」(MAD)。
研究發現在使用AI數據,經過第5次疊代訓練後,模型就會患上MAD。
在合成數據上訓練AI模型會逐漸放大偽影,這其中的機理,和生物學上因「近親繁殖」導致後代產生缺陷的情況十分類似。
正如近親繁殖中的個體因遺傳池縮小而限制了遺傳多樣性,過度依賴AI生成的數據,也會限制模型學習的多樣性,
因為它反映的是前代模型的固有的理解,而非原始的真實世界多樣性。
如果將模型比作人的話,那麼任何模型,即使數據質量再高,也始終會存在稀缺的內容,就像一個人的基因即使再好,也總會存在某些稀缺的因子。
這些「缺陷」在前代模型中不明顯或可接受,通過疊代訓練過程,這些缺陷仍有可能被放大,尤其是在缺乏外部多樣性的情況下。

研究還發現,提高合成質量會損害合成多樣性。
對大模型來說,如果想表現出更好的泛化能力(所謂的舉一反三),就需要不斷適應新的數據和場景,應對新的挑戰,從而總結出新規律、新關聯。
這就是為什麼數據多樣性,對模型如此重要的原因。
既然這中文網際網路上的高質量數據,本來就不是很多,合成數據這條路,從技術上似乎也很難走得通,那麼國產視頻大模型想要超過Sora,還能有哪些路子呢?
自我進化
如果有一種辦法,能讓模型在自己生成數據的同時,不陷入「自噬」的漩渦,還能不斷自我進化,這豈不美哉?
講真,國內已經有部分AI企業走出了這條路子,例如智子引擎團隊開發的新型多模態大模型——Awaker1.0就是這麼個例子。

簡單地來說,Awaker1.0這個模型,之所以能突破以往的數據瓶頸,主要歸功於自身獨特的三大功能:
自動生成數據、自我反思、持續更新。
首先,在自動生成數據方面,Awaker1.0主要通過網絡和物理世界兩種途徑來搜集數據,也就是說,它不光在網上到處搜索,看新聞、讀文章、學東西,還能在跟真實世界裡的智能設備配合時,通過攝影頭看東西、聽聲音,理解周圍發生的事兒。
不過,與簡單的數據爬取不同的是,在搜集了這些多模態的數據後,Awaker1.0還能理解和消化這些信息,並以此生成新的內容,比如文字、圖像甚至視頻。之後再根據這些「反芻」後的內容,不斷優化和更新自己。
接下來,強化後的Awaker1.0可以生成質量更高、更有創意的新數據,如此循環往復,就形成了一個自我訓練的閉環。

換句話說,這實際上是一種動態合成數據的方法,外部數據只是給它提供了「種子」,通過不斷地自生自吞,它可以不斷放大和擴展這些初始數據,持續為自己生成新的訓練數據。
這就像是一個強悍的「增程發動機」,則巧妙地利用了少量的燃料(數據),通過一個循環放大的過程,產生出遠超燃料本身能量的動力輸出。

同時,為了在這個閉環中,糾正數據可能的偏差,Awaker1.0不僅會對生成的數據進行質量評分和反思,過濾掉質量不高的樣本,並且還會通過持續在線學習和疊代,根據新的外部數據和反饋,確保數據的實時性和準確性。
如此一來,模型既避免了受限於有限的外部數據源,也避免了陷入純合成數據可能導致的「模型自噬」現象。
而這種自我反饋和學習的機制,實際上也暗合了AI領域要統一理解側和生成側的想法。
Sora問世後,越來越多聲音表示,要通往AGI,必須達成「理解和生成的大一統」。
這是因為,人類智能的本質就是對世界的理解和創造,目前的AI往往是專門從事理解任務(如分類、檢測)或生成任務(如語言模型、圖像生成)。但真正的智能需要打通理解和生成,形成閉環。

說白了,要讓AI模仿人類大腦的學習模式,邊看邊想,同時在自我輸出的過程中,根據不斷變化的現實進行反思和調整。
用中國人的話來說,就是知行合一。
AI要做到這一點,就需要能夠自己生成數據來訓練自己,並從中不斷成長,隨著時間推移而不斷進化。
這樣,即便面對從未見過的新情況,AI也能像人一樣,靈活應對,甚至有所創造,這就是在實現AGI上的重要一步。



















{kind=link}