
18日凌晨,IBM自主辯論人工智慧(AI)系統Project Debater登上了國際學術頂刊《自然》(Nature)的封面。
僅需喝一杯咖啡的時間,該系統就能學習分析4億篇報導文章。
這個IBM最強AI辯手,可以自如地現場與人類專業辯手進行合乎邏輯地辯論,既能自行組織開場發言,又能駁斥對方辯手的論點。
最終,Project Debater在78類辯題中獲得接近人類專業辯手的平均評分。
數十年來,AI系統在人機大戰中屢屢奪魁。1997年,IBM「深藍」系統擊敗西洋棋冠軍;14年後,IBM「沃森」系統在《Jeopardy!》問答節目中打敗人類明星選手;2016年,谷歌AlphaGo擊敗世界圍棋冠軍……但IBM研究人員認為,這些遊戲競賽類AI仍存在於AI的「舒適區」中。
他們有許多共性:對贏家和固定規則都有明確的定義,便於AI用強化學習找出確保勝利的策略……但辯論AI不具備這些條件,評分權掌握在人類觀眾手中,AI也不可能用一種人類無法遵循的策略來取勝。

因此,在辯論領域,人類仍處於上風,辯論AI的挑戰在AI舒適區之外。
針對這一難題,IBM研究人員自2012年啟動了一項新任務——研發一個完全自主、能與人類實時辯論的AI系統,即Project Debater。
一、自主辯論超出了以往語言研究工作範疇
2019年2月,2021年歐洲大學辯論競標賽冠軍Harish Natarajan參加了一場特殊的辯論,他站在約800名現場觀眾面前,和黑柱狀的計算機打了一場辯論賽。

▲Ranit Aharonov博士(左)、Project Debater(中)、Noam Slonim博士(右)
這個計算機是Project Debater,IBM設計的AI辯手系統,聲音為女聲,辯論主題是「是否應該對學前教育進行補貼?」
辯題公布後,比賽雙方分別有15分鐘的時間來梳理自己的想法,然後雙方交替發表長達4分鐘的開場發言、長達4分鐘的第二輪反駁對手的發言,最後各自發表2分鐘的結束陳詞。
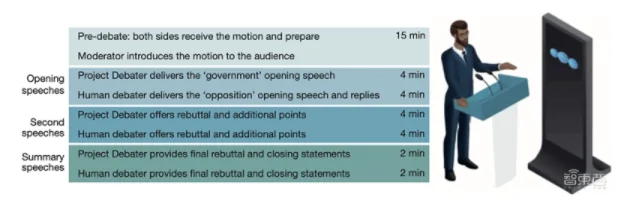
▲辯論流程詳情(來源:Nature)
這是Project Debater首次公開展示辯論能力,儘管它輸了當時的比賽,但它的超強總結能力和擬人化溝通能力給對手和觀眾都留下了深刻印象。
語言修辭和辯論一直是人類獨具的藝術。亞里士多德認為,雄辯的藝術建立在可信度(Ethos)、感染力(Pathos)、邏輯結構(Logos)這三種基本的說服方法上。而在這場辯論賽上,AI系統成功地展示了所有三種說服方法。
AI辯手雖然沒能首戰告捷,不過IBM研究主管Dario Gil說,它的目標並不是擊敗人類,而是創造能掌握複雜豐富的人類語言能力的AI系統。
通過分析人類話語,找到支撐論點的論據,對於幾年前的AI來說還是相當難達到的能力。
如今,全球有50多個實驗室在研究這一問題,其中包括許多大型軟體公司的研究團隊。
近年來,語言模型在理解任務方面取得實質性進展。對於簡單的任務,比如預測給定句子的情感,最先進的系統往往能表現最好;而在更複雜的任務上,如自動翻譯、自動摘要、對話系統,AI系統仍不能達到人類水準。
而辯論是一種同時需應用廣泛語言理解和語言生成能力的人類思維認知活動,自主辯論制度似乎超出了以往語言研究工作的範疇。
對此,IBM研究實驗室已經訓練了其最新的自主AI系統,並在最新發表於《自然》期刊的論文中,全面描述了該系統在廣泛議題中的表現結果。
二、自主辯論AI系統的四大核心模塊
IBM這篇論文的題目為《一個自主辯論系統(An autonomous debating system)》。
具體來看,Project Debater系統由4個主要模塊組成:論點挖掘、論據知識庫(AKB)、論點反駁和論證構建。
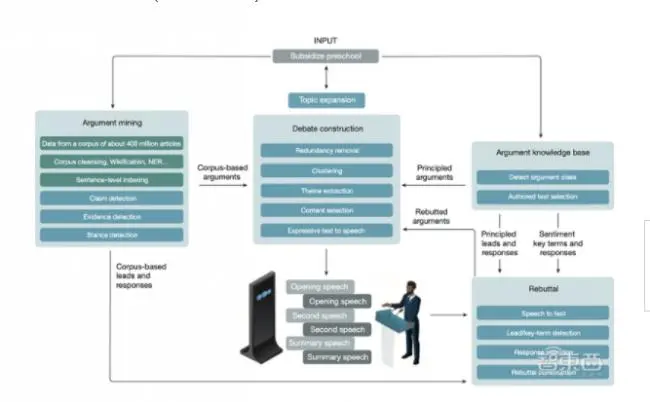
▲辯論AI系統架構(來源:Nature)
1、論點挖掘:從4億篇文章索引相關句
論點挖掘分為兩個階段。
在離線階段,基於約有4億篇報導文章的大型語料庫),把文章分解成句子,通過分析其中的單詞、維基百科概念、預定義詞彙等來索引句子。
到在線階段,獲知辯題後,系統就依賴此索引進行全語料庫的句子級論點挖掘,檢索出與辯題相關的立場主張和論據。
首先,AI系統先用定製查詢檢索含有此類論點傾向性高的句子。接著,根據這些句子代表相關論點的概率,用神經模型對它們進行排序。最後,結合神經網絡和基於知識的方法,對每個接近辯題的論點立場進行分類。
在此階段,系統還使用了主題擴展組件來更好地覆蓋相關論點的範圍。如果該組件識別出與辯題相關的其他概念,它會讓參數挖掘模塊也搜索描述這些概念的論據。
此外,論點挖掘模塊還搜索支持另一方的論據,目的是準備一組對手可能使用的論據和可能作為回擊的證據,該操作稍後由論點反駁模塊使用。
2、AKB:捕捉不同辯論之間的共性
論據知識庫(AKB)的文本包含原則性論點、反論點和可能與廣泛辯題相關的常見例子。這些文本由人工編寫,或自動提取然後人工編輯,並分組成專題類。
給定一個新的辯題,該系統能使用基於特徵的分類器,來確定哪些類與該辯題相關。
然後,所有與匹配類相關聯的文本可以用在發言中,系統基於它們與辯題的語義關聯性,來選擇那些它預測最相關的文本。
這些文本不僅包括論點,還包括鼓舞人心的引語、豐富多彩的類比、辯論的適當框架等等。
3、論點反駁:提前預判對方論點
論點反駁方面,系統會使用論點挖掘模塊、AKB模塊和從iDebate中提取的論點,編譯一個可能被對手提及的論據列表,將其稱之為「線索」。
接下來,IBM「沃森」系統會用到其針對定製語言和定製聲學模型的自動語音到文本服務,將人類對手的語音轉換為文本,然後由神經模型將獲得的文本分解成句子,並添加標點符號。
下一步,專門的組件會確定哪些提前預測的論據確實由對方陳述,並針對性提出反駁。除了這種基於主張的反駁之外,AKB關鍵情感術語也被確定並作為簡單反駁形式的索引。
4、論證構建:組合構建語音發言
論證構建模塊是一個基於規則的系統,集成了聚類分析。在刪除被預先指定為冗餘的參數之後,剩餘參數根據語義相似性進行聚類,每一類都會確定一個主題,類似於一個維基百科的概念。
系統會選擇一組高質量的論點,然後用各種文本規範化和重新措辭技術來提高流利度,最後用預定義的模板逐段生成每個語音陳詞,從而完成與對手的辯論交流。
三、AI辯論表現接近專業人類辯手
由於沒有公認能判定輸贏的單一指標,評價一個辯論系統的表現有挑戰性。
在公開辯論中,觀眾在辯論前後的投票能決定獲勝的一方,但這種方法存在局限性。
如果辯前投票高度不平衡,辯前票數高的持方負擔更大。比如,在2019年2月的人機辯論賽中,賽前79%觀眾支持AI持方,只有13%觀眾支持人類持方,因此AI只能再說服21%觀眾,而人類選手有可能說服87%的其他觀眾。
此外,投票涉及個人意見,難以量化和控制,而創造一個有大量公正觀眾的現場辯論非常困難。
為了評估Project Debater的總體性能,研究人員將其與各種基線進行比較,由15位虛擬觀眾對AI系統及專業人類辯手的辯論表現進行打分,涉及78個辯題。
除了Project Debater外,研究人員沒有發現任何其他能參與完整辯論的方法,因此比較範圍相對有限。
在圖a中,條形圖代表平均得分,從5到1對開場發言的同意程度遞減,5代表「非常同意」,1代表「強烈反對」。斜紋條代表系統中的演講由人產生,或依賴於人工整理的論據。
結果可見,Project Debater的平均得分均最接近專業人類辯手的平均得分。
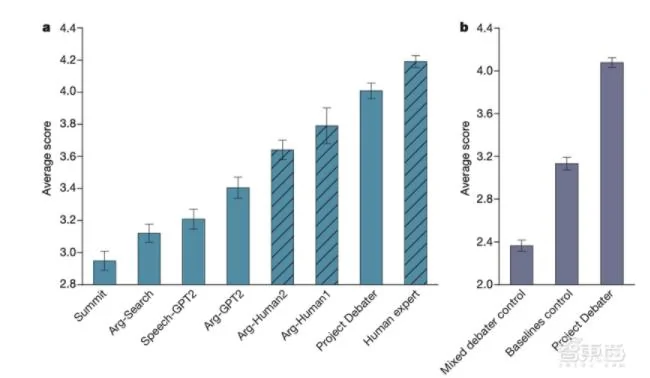
▲辯論評分比較(來源:Nature)
在對最終系統的評分中,研究人員同樣涵蓋了78個辯題。20位評分員觀看了3類辯論陳詞,並在不知道它們來源的情況下進行打分。
結果如圖b,Project Debater在所有辯題的平均得分均高於中立分數3分,78個辯題中有50個辯題的平均得分超過4分,說明在至少有64%的辯題中,評分員認為Project Debater的表現不錯。
不過,儘管評分超過基線和對照組,但Project Debater的表現仍與人類辯手存在明顯差距。
四、評分高的辯題更加切題
為了克服更多挑戰,在後續的定期評估中,研究人員對一組獨立的36個辯題進行額外評估,結果表明Project Debater的過擬合程度很小。
通過進一步分析這36個辯題的結果,研究人員發現,其錯誤大致可分為局部錯誤、影響語音中的特定內容單元,以及通過多個元素傳播並影響整個語音的更廣泛錯誤。
最常見的局部錯誤類型是錯誤的分類論點立場,比如內容離題、不合整體的敘事連貫性;在廣泛性錯誤中,同一類型的錯誤在整個發言過程反覆出現。
研究人員將這些辯題分為3組,根據評分注釋為「高」(3.5分以上)、「中」(3-3.5分)、「低」(3分以下)。
值得注意的是,廣泛錯誤只發生在「低」組,相反,局部錯誤一定程度上幾乎出現在所有辯題,包括在「高」組。
此外,各組之間最明顯的差異是三次陳詞的內容量。從總字數來看,「高」、「中」、「低」辯題的平均字數分別是1496字、1155字、793字。
這種「低」辯題的標誌反映了構建一個系統的挑戰,該系統依賴於許多組成的輸出,是為了能在各種主題上產生精確的輸出。
具體來說,為了讓系統找到相關內容,必須在語料庫中討論辯題的主題,而對於要包含在最終輸出中的特定內容單元,必須通過多個置信度閾值,為確保高精度,這些閾值被設置的很嚴格。
這反過來有可能導致很多相關內容會被過濾掉,因而生成幾分鐘的口語內容是個艱巨的任務。
另一個顯著特點是由AKB組成在開場和結束陳詞時提供敘事框架的質量。「高」辯題通常包含框架元素,這準確地捕捉到了辯論的本質;而「中」辯題的框架往往是可以接受的,但不那麼切題。
最後,研究人員分析了覆蓋整個系統輸出的5種內容類型的詞頻:論點挖掘、AKB、反駁、反駁線索、「罐裝」文本(人類預先編寫的句子片段)。
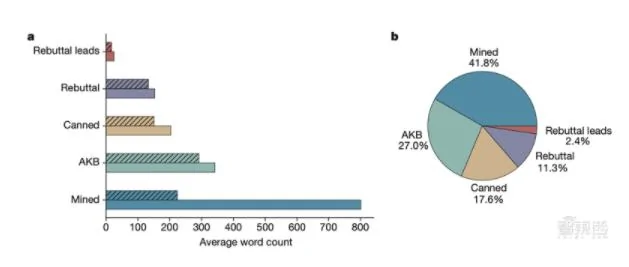
▲內容類型分析(來源:Nature)
如圖,所有類型中,「低」辯題的內容量相對較少,與此前分析一致。最大差距體現在挖掘的內容,進一步表明,高質量的輸出與被檢查語料庫中豐富的相關論據、精確的論點挖掘模塊有關。
此外,研究人員研究了在其原始評估集中所有78個辯題所有陳詞的內容類型相對分布。其中,不到18%的內容是傳統「罐裝」文本,其餘內容則由更高級的底層系統組成提供。
五、AI薄弱環節:模仿人類辯手的連貫性
蘇格蘭鄧迪大學計算機科學家Chris Reed認為,從Project Debater的實時性能來看,IBM團隊的成就很明顯,不僅使用從巨大的數據集中提取的知識,而且還能即時回應人類的話語。
他也提到,這一系統的最薄弱環節,或許是它在努力模仿人類辯手的連貫性和流動性。該問題與論據選擇、抽象表達、論點編排的最高層次相關。
不過,這一限制並非Project Debater所獨有。
儘管人類兩千多年來一直在研究,但對論據結構仍認識有限。
根據論證研究的重點是語言使用、認識論、認知過程還是邏輯有效性,人們對於論證和推理的連貫組合已提出的關鍵特徵各不相同。
辯論技術系統面臨的最後一個挑戰是,是將辯論視作受一系列單一考慮因素影響的局部論述片段,還是將其編入更大範圍的社會規模辯論中。
在很大程度上,這是設計要解決的問題,而不是設計解決方案。
通過在論點上設置先驗界限,可以實現理論上的簡化,從而提供主要的計算優勢。識別的「主要需求」就成了一個明確任務,機器幾乎可以像人類一樣可靠地完成這項任務。
問題在於,人類根本不擅長這項任務,這恰恰是因為它是人工設計的。
在公開討論中,給定範圍的論述可能是在一種情況下的主張,另一種上下文的前提。此外,在現實世界中,沒有明確的界限來界定一個論點:發生在辯論室之外的話語不是離散的,而是與交叉引用、類比、例證和概括相聯。
關於AI如何解決此類論證網絡的想法已有理論提出。但與這些實現方式相關的理論挑戰和社會技術問題是巨大的。
設計吸引大量受眾的方式進入此類系統,就像設計直接的機制使他們能夠與這些複雜的論證網絡進行活動一樣困難。
結語:從辯論AI的野心,看AI系統的未來
無論是作為AI系統還是對AI領域的巨大挑戰,Project Debater都具有極大的野心。
AI和NLP的研究往往集中在「狹義AI」上,這類任務需要的資源較少,通常有明確的評估指標,並能接受端到端解決方案。
相反,「複合AI」任務與更廣泛的人類認知活動相關,需要同時應用多種技能,較少被AI社區處理。IBM將複合AI任務分解成一組有形的、狹窄的任務,並為每個任務開發了相應的解決方案。
結果表明,一個適當組織這些組件的系統,可以有意義地參與複雜的人類活動,IBM研究人員認為,這是不容易接受單一的端到端解決方案的。
IBM的研究,說明AI有參與複雜人類活動的能力。
Project Debater所挑戰的難題,遠遠超出了當前AI技術的舒適範圍。它提供了一個令人期待的前景,當AI能更好地理解人類語言,同時變得更加透明和可解釋,人類也將能在AI的幫助下做出更好的決策。
鑑於虛假新聞如火如荼、輿論兩極分化和惰性推理等現象普遍存在,AI能在人類在創建、處理和共享複雜論點等方面提供支持。
正如在舊金山的展示中,Project Debater問候對手時說到的那句:「我聽說您在與人類辯論比賽的勝利中保持了世界紀錄,但恐怕您從未和機器辯論過。歡迎來到未來。 」

















{kind=link}