巴克萊分析顯示,頂尖AI模型已接近人類專家水平,Claude Opus4.1獲得47.6%勝率領先。AI在零售貿易等領域已超越人類,在軟體開發等職業表現優異。更令人震驚的是,AI能力在15個月內提升3倍,呈線性增長趨勢。預測未來12-24個月內AI將在大多數工作任務上全面超越人類專家。
OpenAI最新發布的GDPval-v0評測工具首次量化了AI在執行具有經濟價值工作任務方面的能力,結果顯示AI正迅速追趕甚至逼近人類專業人員水平。巴克萊表示,最先進的AI模型已在諸多職業任務中達到與人類專家相當的能力,並且這種能力提升速度正在加快。
此前文章寫道,OpenAI最新發布了一款名為GDPval-v0的全新評估工具,涵蓋美國GDP占比較大的九個商業領域中44個職業的約1300項具體工作任務,從法律文書到工程藍圖再到護理計劃等真實工作交付成果。
結果顯示,當前最頂尖的AI模型在執行許多職業任務時,其能力已與人類專業人士相當,並且這種能力的提升速度正在加快。10月5日,據硬AI消息,巴克萊在最新研究報告中稱,Anthropic的Claude Opus4.1在與人類專家對比中取得47.6%的"勝利或平局"率,位居榜首。
巴克萊分析師認為,AI模型的"勝率"在過去15個月中線性提升約4倍,預計在未來12-24個月內AI將在大多數工作相關任務上超越人類。分析認為,這一突破為評估AI投資報酬率提供了關鍵數據支撐。
評測標準創新突破:模擬真實工作複雜性
據巴克萊研究報告,GDPval基準測試的核心創新在於其真實性和複雜性。
該評測由平均擁有超過14年行業經驗的資深專業人士設計,涵蓋科技服務、金融保險、醫療保健、信息業、製造業等行業的1230個專業任務。
與傳統基準測試不同,GDPval的任務並非簡單文本問答,而是包含參考文件和上下文的複雜場景,要求AI交付多樣化成果,包括文檔、幻燈片、圖表和電子表格等。巴克萊指出,這種設計更貼近現實工作環境的複雜性。
評測採用盲測方式,由行業專家對AI和人類生成的工作成果進行排名,從難度、代表性、完成時間和整體質量等維度進行綜合評估。
AI性能接近人類專家水平
巴克萊分析顯示,當前最先進的AI模型在多個領域已接近或達到人類專家水平。Claude Opus4.1以47.6%的勝率領先,GPT-5-high緊隨其後,達到38.8%,o3 high為34.1%。
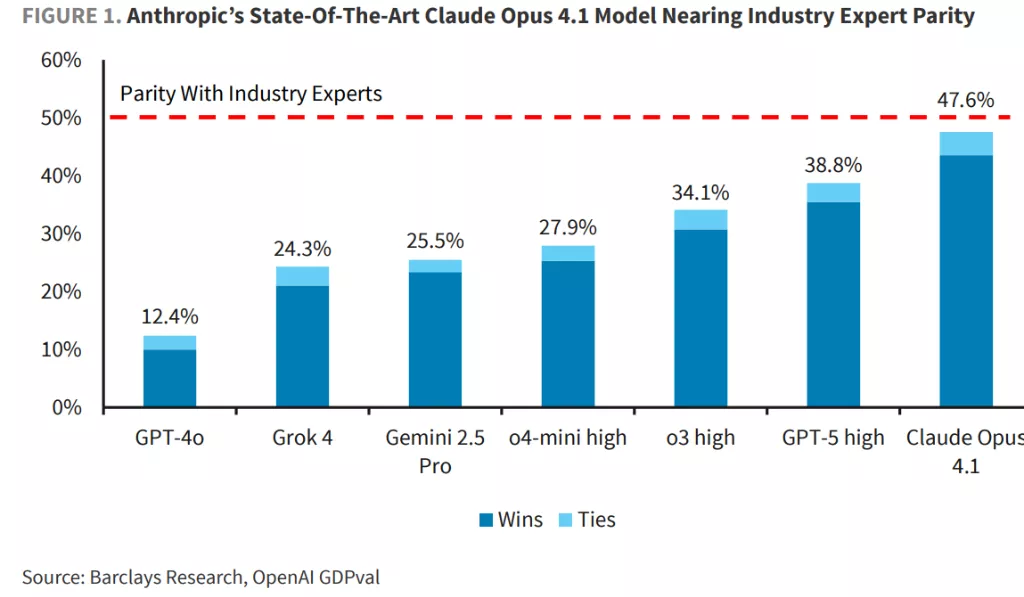
從行業維度看,AI在零售貿易(56%勝率)、批發貿易(53%)和政府部門(52%)的表現超過人類專家,但在資訊技術行業表現相對較弱(39%)。
職業層面上,AI在櫃檯和租賃文員(80%)、運輸接收和庫存文員(76%)以及軟體開發人員(70%)任務中表現最佳,而在工業工程師(17%)和影視編輯(17%)任務中表現較差。
各模型表現出不同特點:Claude Opus4.1在美學表現(格式和布局)方面表現出色,GPT-5在遵循指令和執行準確計算方面最為精準。
能力提升速度驚人
巴克萊報告特別強調了AI能力提升的速度。
研報稱,OpenAI模型在GDPval測試中的表現在15個月內提升了3倍以上,這種線性增長趨勢表明AI很可能在短期內全面超越人類專家。
對GPT-5的失誤分析顯示,儘管該模型仍會犯一些災難性錯誤(2.7%),但47.7%的失誤被歸類為"可接受但不佳",22.9%的情況下模型表現甚至優於人類。
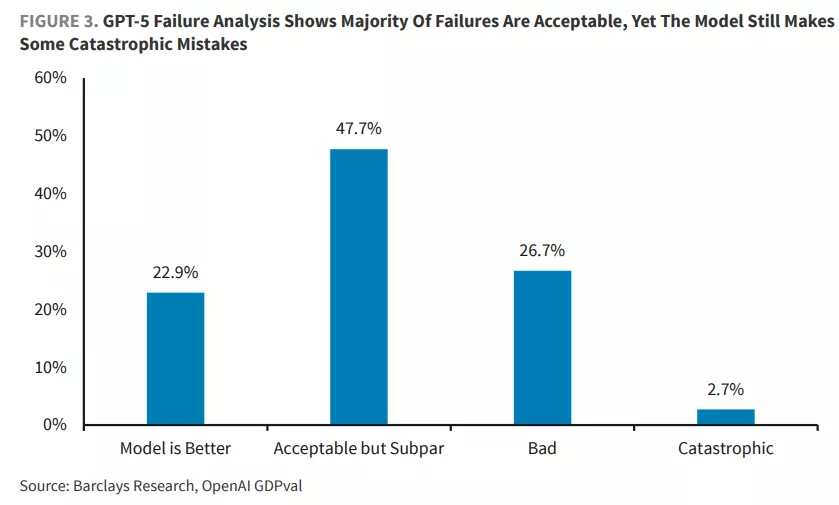
巴克萊分析師認為,AI模型的原始智能,特別是GPT-5.已達到超越人類專家的水平。通過更多後期訓練(微調、強化學習),AI全面超越行業專家的時代已為時不遠。

















{kind=link}